С 21 по 24 мая проводилась конференция EMC World 2012, где одной из главных тем были, конечно же, решения по защите данных и балансировки нагрузки между географически распределенными датацентрами. Прежде всего были анонсированы решения EMC VPLEX 5.1 и RecoverPoint 3.5:
По-прежнему, SRA-адаптера для совместного решения VMware SRM+VPLEX до сих пор нет, потому как, похоже, нет окончательной ясности, нужен ли SRM, когда есть VPLEX Metro с синхронизированными томами между датацентрами и "растянутый кластер" VMware vMSC (vSphere Metro Storage Cluster) между хостами датацентров. Безусловно, сотрудники EMC говорят, что решения взаимодополняющие (т.к. SRM - это план восстановления после сбоев, а не схема катастрофоустойчивости), но пока SRM предлагается использовать только в схеме с решением для защиты данных EMC RecoverPoint, для которого SRA-адаптер уже есть:
Появилась также поддержка разнесенных active/active кластеров Oracle RAC в EMC VPLEX:
С точки зрения vSphere Metro Storage Cluster также появилась пара интересных новостей. Во-первых, документ "VMware vSphere Metro Storage Cluster Case Study", описываещий различные сценарии отказов в растянутом кластере высокой доступности (vMSC), построенном между двумя географически разнесенными площадками:
В последнее время становится все больше и больше компаний, предоставляющих сервисы аренды виртуальных машин в облачной инфраструктуре на платформе VMware vSphere. Между тем, защищенности таких инфраструктур и их соответствию стандартам безопасности (особенно российским), как правило, уделяется мало внимания. Сегодня мы поговорим о том, что можно сделать с помощью продукта vGate R2 для защиты виртуальных сред в датацентрах провайдеров, предоставляющих виртуальные машины VMware в аренду.
Не секрет, что в последнее время пользователи виртуальной инфраструктуры VMware vSphere серезно задумываются о ее защите, а также о соответствии российскому законодательству, поскольку, зачастую, в виртуальных машинах обрабатываюся персональные данные. Кроме того, организации тратят большие деньги на организацию и исполнение процедур по настройке безопасности виртуальных сред в соответствии с руководящими документами и стандартами (это ручные и трудоемкие операции).
На вебинаре менеджер по развитию продукта Александр Лысенко расскажет о программном продукте vGate - лидирующем на российском рынке решении для защиты систем управления виртуальных инфраструктур на платформе VMware.
Будут рассмотрены угрозы информационной безопасности, возникающие при использовании виртуализации и способы их нейтрализации. Отдельно докладчик остановится на требованиях законодательства, отраслевых стандартах и лучших практиках в области информационной безопасности виртуализированных систем.
Будут представлены схемы использования vGate и других продуктов разработки «Кода Безопасности» для решения ИБ-задач в виртуальных инфраструктурах.
Как известно, в VMware vSphere 5 появилось несколько полезных нововведений, касающихся сетевого взаимодействия, доступных в распределенном коммутаторе VMware vSphere Distributed Switch (vDS), которые облегчают жизнь сетевым администраторам. В частности, посредством dvSwitch доступны следующие новые возможности, которые описаны в документе "What's New in VMware vSphere
5.0
Networking":
Поддержка Netflow версии 5 - возможность просмотра трафика между виртуальными машинами (ВМ-ВМ на одном или разных хостах, а также ВМ-физический сервер) посредством сторонних продуктов, поддерживающих Netflow.
Поддержка зеркалирования портов Switch Port
Analyzer (аналог технологии SPAN в коммутаторах Cisco) - возможность дублировать трафик виртуальной машины (а также VMkernel и физических адаптеров) на целевую машину (Port Mirroring), которая может реализовывать функционал системы обнаружения или предотвращения вторжений (IDS/IPS).
Поддержка открытого стандарта Link Layer Discovery Protocol (LLDP, в реализации 802.1AB) - это механизм обнаружения соседних сетевых устройств и сбора информации о них для решения различных проблем сетевыми администраторами. Ранее поддерживался только протокол CDP (Cisco Discovery Protocol), поддержка которого есть не во всех устройствах.
Улучшения механизма Network I/O Control - пулы ресурсов для сетевого трафика и поддержка стандарта 802.1q. Опредлеямые пользователем пулы для различных типов трафика позволяют приоритезировать и ограничивать пропускную способность канала для них посредством механизма shares и limits.
Все эти новые возможности мы разберем в следующих заметках, а сегодня сосредоточимся на механизме Netflow и его поддержке в vSphere 5. NetFlow — сетевой протокол, предназначенный для учёта сетевого трафика, разработанный компанией Cisco Systems. Является фактическим промышленным стандартом и поддерживается не только оборудованием Cisco, но и многими другими устройствами.
Для сбора информации о трафике по протоколу NetFlow требуются следующие компоненты:
Сенсор. Собирает статистику по проходящему через него трафику. Обычно это L3-коммутатор или маршрутизатор, хотя можно использовать и отдельно стоящие сенсоры, получающие данные путем зеркалирования порта коммутатора. В нашем случае это распределенный коммутатор vDS.
Коллектор. Собирает получаемые от сенсора данные и помещает их в хранилище.
Анализатор. Анализирует собранные коллектором данные и формирует пригодные для чтения человеком отчёты (часто в виде графиков).
NetFlow дает возможность сетевому администратору мониторить сетевые взаимодействия виртуальных машин для дальнейших действий по обнаружению сетевых вторжений, отслеживания соответствия конфигураций сетевых служб и анализа в целом. Кроме того, данная возможность полезна тогда, когда требуется отслеживать поток трафика от приложений внутри виртуальной машины с целью контроля производительности сети и целевого использования трафика.
Синяя линия на картинке показывает настроенный виртуальный коммутатор, который посылает данные Netflow на стороннюю машину (коллектор), которая подключена к хост-серверу VMware ESXi через физический коммутатор. Коллектор уже передает данные анализатору. Netflow может быть включен на уровне отдельной группы портов (dvPortGroup), отдельного порта или аплинка (Uplink).
Для начала настройки Netflow нужно зайти в свойства коммутатора vDS (он должен быть версии 5.0.0 или выше):
Здесь мы указываем IP-адрес коллектора, куда будут отправляться данные, его порт, а также единый IP-адрес коммутатора vDS, чтобы хосты не представлялись отдельными коммутаторами для коллектора.
Включить мониторинг Netflow можно в свойствах группы портов на vDS в разделе Monitoring:
Далее в эту группу портов включаем одну из виртуальных машин:
Теперь можно использовать один из продуктов для сбора и анализа трафика Netflow, например, Manage Engine Netflow Analyzer. Пример статистики, которую собирает этот продукт по протоколам (в данном случае большинство трафика - http):
Netflow можно использовать для различных целей мониторинга, например, в инфраструктуре VMware View, где присутствуют сотни виртуальных машин, можно сгруппировать трафик по группам и смотреть, сколько трафика выжирается видеосервисами (Youtube, к примеру), так как это может сильно влиять на производительность сети в целом:
Применений Neflow на самом деле уйма, поэтому его поддержка в VMware vSphere 5 может оказаться вам очень полезной.
Мы уже не раз писали о типах устройств в продукте StarWind iSCSI Target, который предназначен для создания отказоустойчивых iSCSI-хранилищ для серверов VMware vSphere и Microsoft Hyper-V, однако с тех времен много что изменилось: StarWind стал поддерживать дедуплицированные хранилища и новые типы устройств, которые могут пригодиться при организации различных типов хранилищ и о которых мы расскажем ниже...
Таги: StarWind, iSCSI, SAN, Enteprirse, HA, Storage, VMware, vSphere
На проходящих сейчас по всему миру мероприятиях VMware Partner Exchange On Tour (PEX) сотрудники VMware все больше рассказывают о возможностях новой версии платформы виртуализации серверов VMware vSphere 5.1. Во-первых, стало известно, что vSphere 5.1 будет анонсирована на предстоящем VMworld, который пройдет в Сан-Франциско с 27 по 30 августа этого года.
Во-вторых, во всяких твиттерах появилось описание некоторых новых возможностей VMware vSphere 5.1, которые мы увидим осенью этого года, а именно:
Поддержка технологии кластеров непрерывной доступности Fault Tolerance для виртуальных машин с несколькими виртуальными процессорами (vCPU).
Загрузка хостов через адаптеры Fiber Channel over Ethernet (FCoE).
Поддержка виртуализованных контроллеров домена Active Directory. Windows Server 8, который исполняется в виртуальной машине, на самом деле в курсе, что он работает в ВМ. Это означает, что создание и удаление снапшота такой машины не приведет к проблемам с AD, возникающих с номером последовательного обновления (Update Sequence Number, USN) контроллера. Ранее при восстановлении из снапшота из-за проблем с USN могла остановиться репликация данных каталога. Теперь Microsoft добавила технологию Generation ID, которая позволяет виртуальному контроллеру домена знать, последняя ли версия каталога им используется. За счет этого решаются проблемы с репликацией при откате к снапшоту, а также появляется возможность клонирования виртуальных машин с контроллерами домена. Соответственно, такую возможность и будет поддерживать vSphere 5.1.
Что касается технологии Fault Tolerance для ВМ с несколькими vCPU, то, как пишут наши коллеги на vMind.ru, эта технология будет требовать соединения 10 GigE для работы механизма "SMP Protocol", который придет на смену технологии vLockstep. При этом работать она сможет вообще без общего хранилища для виртуальных машин, которые могут быть разнесены по разным датасторам и хостам:
Безусловно, это не все новые возможности, которые следует ожидать в VMware vSphere 5.1, поэтому мы будем держать вас в курсе новых подробностей по мере их поступления.
Если вы являетесь разработчиком и администраторов скриптов PowerCLI / PowerShell для автоматизации операций в виртуальной инфраструктуре VMware vSphere, вам, наверняка, часто приходится хардкодить логин и пароль для соединения с сервером vCenter или вводить их в интерактивном режиме. Это не очень безопасно (мало ли кто увидит ваш скрипт на экране), да и вообще, не очень удобно.
Специально для этого в PowerCLI есть хранилище, называемое Credential Store, в которое можно помещать логин и пароль от сервера, с которым вы соединяетесь из скрипта.
Таким образом для этого хоста вы помещаете креды "user" с паролем "password" в шифрованное хранилище Credential Store, которое находится в следующем файле:
%APPDATA%\VMware\credstore\vicredentials.xml
Теперь при соединении с vCenter из скрипта, просто пишете:
Connect-VIServer 192.168.1.10
В этом случае, при отсутствии указания логина и пароля, PowerCLI заглядывает в хранилище и смотрит, нет ли там кредов для этого хоста, и если они есть, то подставляет их. Все просто.
Чтобы посмотреть креды из хранилища, нужно просто вызвать следующий командлет:
Такой способ хранения логинов и паролей для скриптов действует для конкретного пользователя, так как они хранятся в Credential Store в зашифрованном виде и могут быть расшифрованы только под ним. То есть, если злоумышленник украдет виртуальную машину с этими скриптами, но не сможет залогиниться под этим пользователем, получить эти пароли он не сможет, при условии использования Windows file encryption (EFS) для файла хранилища.
Есть также и альтернативный метод хранения кредов для скриптов в произвольном файле.
Интересная штука обнаружилась среди средств управления и мониторинга инфраструктуры VMware vSphere - Cloud Resource Meter от компании 6fusion, которая специализируется на утилитах для облачных сред. Это такая штука, которая реализована в виде виртуального модуля (Virtual Appliance), позволяющая оценить облачную инфраструктуру vSphere "в попугаях", то есть в специальных единицах Workload Allocation Cube (WAC), потребляемых за час. Убеждают, что алгоритм этого WAC - не хухры-мухры, а patent pending.
Этот WAC - это шестимерная сущность, представляющая собой эталонную совокупность ресурсов, потребляемых виртуальной машиной в облаке, а именно:
Вот в количестве таких шестигранных кубиков вы и увидите каждую из виртуальных машин своего (или провайдерского) датацентра в реальном времени. Предполагается, что такая модель позволит наиболее адекватно обсчитать вычислительные мощности своего ЦОД (chargeback), вести учет и планировать вычислительные мощности. Облачные провайдеры и менеджеры корпоративных датацентров могут устанавливать параметры и цену такого "вака", что позволит понимать, сколько ресурсов есть в наличии и сколько будет стоить разместить то или иное приложение в облаке.
Для каждой машины ведется исторический учет потребляемых "вакочасов":
Авторы этой программулины утверждают, что алгоритм этих "ваков" был разработан еще в 2004 году для профилирования приложений под ESX 1.0, так что может стоит и посмотреть, что они с тех пор сделали, тем более, что есть бесплатная версия продукта Cloud Resource Meter. На данный момент он, правда, находится в бете, но поддерживает vSphere 4.1 и 5.0.
Ни для кого не скрет, что государственные организации очень часто и очень много работают с персональными данными (ПДн). Не секрет также, что многие госы уже внедрили виртуальную инфраструктуру VMware vSphere, где есть виртуальные машины, которые эти данные хранят и обрабатывают, что требует соответствующих мер и технических средств защиты, сертифицированных ФСТЭК. К сожалению, сама платформа VMware vSphere имеет недостаток, который я называю "Lack of ФСТЭК", то есть отсутствие своевременно обновляемых сертификатов ФСТЭК на продукт (сейчас актуален сертификат на vSphere 4.1, и нет информации, когда будет сертифицирована пятерка).
Поэтому, когда есть персональные данные и инфраструктура vSphere, просто необходимо использовать единственный имеющийся сейчас на рынке сертифицированный ФСТЭК продукт vGate R2, который позволяет автоматически настроить среду VMware vSphere в соответствии с требованиями общепринятых и отраслевых (специально для России) стандартов, а также защитить инфраструктуру от НСД.
Ниже приведена выдержка из описания кейса внедрения vGate R2 для ТФОМС Приморского края, где была необходима сертифицированная защита среды VMware vSphere:
Перед IT–специалистами и сотрудниками отдела информационной безопасности Фонда была поставлена задача обеспечить в 2011 году защиту информационных массивов персональных данных застрахованных граждан, эксплуатируемых в Фонде по классу информационной безопасности К1.
...
Для выполнения задач защиты системы обработки персональных данных были выбраны продукты vGate и Secret Net 6.5 разработки компании «Код Безопасности».
Реализация проекта по развертыванию ПО vGate осуществлялась на вновь создаваемом ресурсе в виде изолированной аппаратной платформы и развернутой на этой платформе виртуальной инфраструктуры на базе технологии VMware.
Связь с защищенным сегментом осуществляется через аппаратный терминальный клиент, обеспечивающий двухфакторный контроль доступа в защищенную среду центра обработки персональных данных.
Начальник отдела автоматизированной обработки информации ГУ ТФОМС ПК Воробьев П.Б.отметил, что в результате развертывания программного решения vGate для защиты виртуальной инфраструктуры центра обработки персональных данных были решены следующие задачи:
обеспечена защита персональных данных, хранящихся и обрабатываемых в виртуальной среде (ЗСОПДн) от утечек через каналы, специфичные для виртуальной инфраструктуры (контроль виртуальных устройств, обеспечение целостности и доверенной загрузки виртуальных машин и контроль доступа к элементам виртуальной инфраструктуры);
реализовано разделение объектов виртуальной инфраструктуры на логические группы и сферы администрирования с помощью функций мандатного и ролевого управления доступом;
установлен контроль над изменениями настроек безопасности на основе утвержденных корпоративных политик безопасности;
сконфигурирован и запущен в работу АРМ администратора системы безопасности;
реализована регистрация попыток доступа в инфраструктуру, также возможность создания отчетов о состоянии виртуальной инфраструктуры и контроля целостности периметра;
работа с персональными данными в ГУ ТФОМС ПК приведена в соответствие с требованиями законодательства РФ в области защиты информации.
Как известно, многие консольные команды старой сервисной консоли VMware ESX (например, esxcfg-*) в ESXi 5.0 были заменены командами утилиты esxcli, с помощью которой можно контролировать весьма широкий спектр настроек, не все из которых дублируются графическим интерфейсом vSphere Client. В списке ниже приведены некоторые полезные команды esxcli в ESXi 5.0, которыми можно воспользоваться в локальной консоли (DCUI) или по SSH для получения полезной информации как о самом хост-сервере, так и об окружении в целом.
1. Список nfs-монтирований на хосте: # esxcli storage nfs list
2. Список установленных vib-пакетов: # esxcli software vib list
3. Информация о памяти на хосте ESXi, включая объем RAM: # esxcli hardware memory get
4. Информация о количестве процессоров на хосте ESXi: # esxcli hardware cpu list
5. Список iSCSI-адаптеров и их имена: # esxli iscsi adapter list
6. Список сетевых адаптеров: # esxcli network nic list
7. Информация об IP-интерфейсах хоста: # esxcli network ip interface list
8. Информация о настройках DNS: # esxcli network ip dns search list
# esxcli network ip dns server list
9. Состояние активных соединений (аналог netstat): # esxcli network ip connection list
10. Вывод ARP-таблицы: # network neighbors list
11. Состояние фаервола ESXi и активные разрешения для портов и сервисов: # esxcli network firewall get
# esxcli network firewall ruleset list
12. Информация о томах VMFS, подключенных к хосту: # esxcli storage vmfs extent list
13. Мапинг VMFS-томов к устройствам: # esxcli storage filesystem
list
14. Текущая версия ESXi: # esxcli system version get
15. Вывод информации о путях и устройствах FC: # esxcli storage core path list
# esxcli storage core device list
16. Список плагинов NMP, загруженных в систему: # esxcli storage core plugin list
18. Получить список ВМ с их World ID и убить их по этому ID (помогает от зависших и не отвечающих в vSphere Client ВМ): # esxcli vm process list (получаем ID) # esxcli vm process kill --type=[soft,hard,force] --world-id=WorldID (убиваем разными способами)
19. Узнать и изменить приветственное сообщение ESXi: # esxcli system welcomemsg get
# esxcli system welcomemsg set
20. Поискать что-нибудь в Advanced Settings хоста: # esxcli system settings advanced list | grep <var>
21. Текущее аппаратное время хоста: # esxcli hardware clock get
22. Порядок загрузки с устройств: # esxcli hardware bootdevice list
23. Список PCI-устройств: # esxcli hardware pci list
24. Рескан iSCSI-адаптеров (выполняем две команды последовательно): # esxcli iscsi adapter discovery rediscover -A <adapter_name>
# esxcli storage core adapter rescan [-A <adapter_name> | -all]
25. Список виртуальных коммутаторов и портгрупп: # esxcli network vswitch standard list
Для тех из вас, кто умеет и любит разрабатывать скрипты на PowerCLI / PowerShell для виртуальной инфраструктуры VMware vSphere, приятная новость - вышло два полезных справочика в формате Quick Reference. Первый - vSphere 5.0 Image Builder PowerCLI Quick-Reference v0.2, описывающий основные командлеты для подготовки образов хост-серверов к автоматизированному развертыванию (а также собственных сборок ESXi) средствами Image Builder:
Мы уже некоторое время назад писали про различные особенности томов VMFS, где вскользь касалисьпроблемы блокировок в этой кластерной файловой системе. Как известно, в платформе VMware vSphere 5 реализована файловая система VMFS 5, которая от версии к версии приобретает новые возможности.
При этом в VMFS есть несколько видов блокировок, которые мы рассмотрим ниже. Блокировки на томах VMFS можно условно разделить на 2 типа:
Блокировки файлов виртуальных машин
Блокировки тома
Блокировки файлов виртуальных машин
Эти блокировки необходимы для того, чтобы файлами виртуальной машины мог в эксклюзивном режиме пользоваться только один хост VMware ESXi, который их исполняет, а остальные хосты могли запускать их только тогда, когда этот хост вышел из строя. Назвается этот механизм Distributed Lock Handling.
Блокировки важны, во-первых, чтобы одну виртуальную машину нельзя было запустить одновременно с двух хостов, а, во-вторых, для их обработки механизмом VMware HA при отказе хоста. Для этого на томе VMFS существует так называемый Heartbeat-регион, который хранит в себе информацию о полученных хостами блокировок для файлов виртуальных машин.
Обработка лока на файлы ВМ происходит следующим образом:
Хосты VMware ESXi монтируют к себе том VMFS.
Хосты помещают свои ID в специальный heartbeat-регион на томе VMFS.
ESXi-хост А создает VMFS lock в heartbeat-регионе тома для виртуального диска VMDK, о чем делается соответствующая запись для соответствующего ID ESXi.
Временная метка лока (timestamp) обновляется этим хостом каждые 3 секунды.
Если какой-нибудь другой хост ESXi хочет обратиться к VMDK-диску, он проверяет наличие блокировки для него в heartbeat-регионе. Если в течение 15 секунд (~5 проверок) ESXi-хост А не обновил timestamp - хосты считают, что хост А более недоступен и блокировка считается неактуальной. Если же блокировка еще актуальна - другие хосты снимать ее не будут.
Если произошел сбой ESXi-хоста А, механизм VMware HA решает, какой хост будет восстанавливать данную виртуальную машину, и выбирает хост Б.
Далее все остальные хосты ESXi виртуальной инфраструктуры ждут, пока хост Б снимет старую и поставит свою новую блокировку, а также накатит журнал VMFS.
Данный тип блокировок почти не влияет на производительность хранилища, так как происходят они в нормально функционирующей виртуальной среде достаточно редко. Однако сам процесс создания блокировки на файл виртуальной машины вызывает второй тип блокировки - лок тома VMFS.
Блокировки на уровне тома VMFS
Этот тип блокировок необходим для того, чтобы хост-серверы ESXi имели возможность вносить изменения в метаданные тома VMFS, обновление которых наступает в следующих случаях:
Создание, расширение (например, "тонкий" диск) или блокировка файла виртуальной машины
Изменение атрибутов файла на томе VMFS
Включение и выключение виртуальной машины
Создание, расширение или удаление тома VMFS
Создание шаблона виртуальной машины
Развертывание ВМ из шаблона
Миграция виртуальной машины средствами vMotion
Для реализации блокировок на уровне тома есть также 2 механизма:
Механизм SCSI reservations - когда хост блокирует LUN, резервируя его для себя целиком, для создания себе эксклюзивной возможности внесения изменений в метаданные тома.
Механизм "Hardware Assisted Locking", который блокирует только определенные блоки на устройстве (на уровне секторов устройства).
Наглядно механизм блокировок средствами SCSI reservations можно представить так:
Эта картинка может ввести в заблуждение представленной последовательностью операций. На самом деле, все происходит не совсем так. Том, залоченный ESXi-хостом А, оказывается недоступным другим хостам только на период создания SCSI reservation. После того, как этот reservation создан и лок получен, происходит обновление метаданных тома (более длительная операция по сравнению с самим резервированием) - но в это время SCSI reservation уже очищен, так как лок хостом А уже получен. Поэтому в процессе самого обновления метаданных хостом А все остальные хосты продолжают операции ввода-вывода, не связанные с блокировками.
Надо сказать, что компания VMware с выпуском каждой новой версии платформы vSphere вносит улучшения в механизм блокировки, о чем мы уже писали тут. Например, функция Optimistic Locking, появившаяся еще для ESX 3.5, позволяет собирать блокировки в пачки, максимально откладывая их применение, а потом создавать один SCSI reservation для целого набора локов, чтобы внести измененения в метаданные тома VMFS.
С появлением версии файловой системы VMFS 3.46 в vSphere 4.1 появилась поддержка функций VAAI, реализуемых производителями дисковых массивов, так называемый Hardware Assisted Locking. В частности, один из алгоритмов VAAI, отвечающий за блокировки, называется VAAI ATS (Atomic Test & Set). Он заменяет собой традиционный механизм SCSI reservations, позволяя блокировать только те блоки метаданных на уровне секторов устройства, изменение которых в эксклюзивном режиме требуется хостом. Действует он для всех перечисленных выше операций (лок на файлы ВМ, vMotion и т.п.).
Если дисковый массив поддерживает ATS, то традиционная последовательность SCSI-комманд RESERVE, READ, WRITE, RELEASE заменяется на SCSI-запрос read-modify-write для нужных блокировке блоков области метаданных, что не вызывает "замораживания" LUN для остальных хостов. Но одновременно метаданные тома VMFS, естественно, может обновлять только один хост. Все это лучшим образом влияет на производительность операций ввода-вывода и уменьшает количество конфликтов SCSI reservations, возникающих в традиционной модели.
По умолчанию VMFS 5 использует модель блокировок ATS для устройств, которые поддерживают этот механизм VAAI. Но бывает такое, что по какой-либо причине, устройство перестало поддерживать VAAI (например, вы откатили обновление прошивки). В этом случае обработку блокировок средствами ATS для устройства нужно отменить. Делается это с помощью утилиты vmkfstools:
vmkfstools --configATSOnly 0 device
где device - это пусть к устройству VMFS вроде следующего:
Продолжаем рассказывать технические подробности о сертифицированном ФСТЭК продукте vGate R2, который предназначен для обеспечения безопасности виртуальной инфраструктуры VMware vSphere (в том числе 5-й версии) средствами политик ИБ и механизма защиты от НСД.
Сегодня мы поговорим о компоненте защиты сервера vCenter, который входит в поставку vGate R2. Это сетевой экран, который позволит вам дополнить решение по защите виртуальной среды VMware vSphere. В его установке нет никаких сложностей - ставится он методом "Next->Next->Next":
Потребуется лишь указать параметры базы сервера авторизации, который должен быть развернут в виртуальной среде (как это делается - тут) и параметры внешней подсети, в которую смотрит сервер vCenter (это сеть, откуда соединяются через клиент vSphere администраторы виртуальной инфраструктуры):
После этого компонент vGate R2 для защиты vCenter будет установлен. У него нет графического интерфейса, поэтому для задания правил сетевого экрана нужно воспользоваться консольной утилитой. Компонент защиты, устанавливаемый на vCenter, осуществляет фильтрацию только входящего трафика.
При этом разрешены только штатные входящие сетевые соединения:
соединения из внешнего периметра сети администрирования через сервер
авторизации
доступ с сервера авторизации на TCP-порт 443 и по протоколу ICMP
доступ на UDP-порт 902 c ESX-серверов
Если необходимо разрешить доступ к vCenter с какого-либо иного направления, то необходимо добавить правила доступа с помощью специальной утилиты
командной строки drvmgr.exe.
Описание некоторых команд утилиты drvmgr.exe и их параметров приведено ниже:
> drvmgr
Вызов справки
> drvmgr i 0x031
Просмотр текущих правил фильтрации
>drvmgr А protocol IP_from[:source_port[,mask]] [:destination_port] [Flags]
Добавление правила фильтрации
>drvmgr R protocol IP_from[:source_port[,mask]] [destination_port] [Flags]
Удаление правила фильтрации
Описание аргументов параметров команд утилиты приведено в таблице:
Например, для добавления правила, разрешающего входящие соединения из сети 172.28.36.0 по любому протоколу на любой входящий порт vСenter, формат команды следующий:
>drvmgr A any 172.28.36.0:any,255.255.255.0 any 4
Для удаления вышеуказанного правила следует указать команду:
>drvmgr R any 172.28.36.0:any,255.255.255.0 any 4
Скачать пробную версию продукта vGate R2 можно по этой ссылке. Презентации по защите виртуальных инфраструктур доступны тут, а сертификаты ФСТЭК продукта - здесь.
Как и ожидалось, компания VMware в самом начале мая объявила о выпуске новой версии решения для виртуализации настольных ПК VMware View 5.1, в которой появилось несколько значимых нововведений и улучшений. Мы уже писали о новой версии View 5.1 (и тут), где был приведен основной список новых возможностей, а в этой статье разберем их подробнее. Основные нововведения VMware View 5.1 перечислены на картинке ниже...
Мы уже писали о продукте для комплексного мониторинга и управления виртуальной инфраструктурой VMware vCenter Operations Management Suite, в состав которого входит ПО для отслеживания взаимосвязей на уровне приложений VMware vCenter Infrastructure Navigator. На днях компания VMware выпустила обновление - VMware vCenter Infrastructure Navigator 1.1.
Напомним, что Infrastructure Navigator - это плагин к vCenter (интегрируется в веб-клиент VMware vSphere 5 Web Client), поставляемый в виде виртуального модуля (Virtual Appliance), который строит структуру взаимосвязей на уровне приложений в виртуальных машинах, что позволяет анализировать завимости уровня приложений и их связ с объектами VMware vSphere.
vCenter Infrastructure Navigator предоставляет следующие основные возможности:
Построение карты сервисов в виртуальной среде для того, чтобы отследить взаимосвязь проблемы отдельного сервиса и виртуальной инфраструктуры. Приложения в виртуальных машинах и взаимосвязи между ними обнаруживаются и добавляются на карту автоматически.
Отслеживание влияния изменений в приложениях на группы сервисов и виртуальную среду в целом для дальнейшего анализа влияния на бизнес-функции виртуальной инфраструктуры.
Ассоциирование объектов виртуальной инфраструктуры с объектами приложений, что позволяет оперировать с объектами vSphere, относящимися к конкретному сервису (например, поиск ВМ, реализующих сервисы Exchange и управление ими).
Поддержка взаимосвязей на уровне приложений для корректного восстановления инфраструктуры на DR-площадке (например, с помощью VMware SRM)
Если обобщить, то vCenter Infrastructure Navigator позволяет отобразить линейный список ваших виртуальных машин в vSphere Client на карту зависимостей сервисов друг от друга (с учетом портов взаимодействия), что позволит понять влияние тех или иных действий с виртуальной машиной или приложением в ней на другие составляющие ИТ-инфраструктуры компании:
То есть, слева у вас просто список машин (в данном случае, в контейнере vApp), а справа - уже карта связей на уровне компонентов приложений.
Новые возможности VMware vCenter Infrastructure Navigator 1.1:
Поддержка продукта VMware vCloud Director (VCD) для облачных сред.
Поддержка внешних взаимосвязей для приложений. Например, сервисов виртуальной машины с сервисами физического сервера, который не управляется vCenter.
Обнаружение неизвестных сервисов - для них просто указывается тип "unknown", имя процесса и порт, на котором сервис слушает.
Возможность задания пользовательского типа сервиса на базе атрибутов: имя процесса, порт.
Поддержка обнаружения следующих сервисов: Site Recovery Manager (SRM) Server, VMware View Server, VMware vCloud Director Server и VMware vShield Manager Server.
Нотификации о различных ошибках на отдельной панели.
Возможность раскрытия объектов карты сервисов из одного представления для вывода необходимого уровня детальности дерева взаимосвязей.
Напоминаем, что VMware vCenter Infrastructure Navigator 1.1 является частью продукта VMware vCenter Operations Management Suite и доступен для загрузки по этой ссылке. Также обновился и сам VMware vCenter Operations Manager (основная часть Suite) до версии 5.01.
Сотрудники компании VMware не так давно на корпоративном блоге публиковали заметки о сравнении протоколов FC, iSCSI, NFS и FCoE, которые используются в VMware vSphere для работы с хранилищами. В итоге эта инициатива переросла в документ "Storage Protocol Comparison", который представляет собой сравнительную таблицу по различным категориям, где в четырех столбиках приведены преимущества и особенности того или иного протокола:
Полезная штука со многими познавательными моментами.
Продолжаем рассказывать о продукте vGate R2, предназначенном для защиты виртуальной инфраструктуры за счет встроенных политик безопасности, обеспечивающих автоматическую безопасную настройку сред VMware vSphere 4.0, 4.1 и 5.0, а также виртуальных машин. Напомним, что vGate R2 - это единственное средство комплексной защиты виртуализации, сертифицированное ФСТЭК.
Одной из полезных особенностей vGate R2 является наличие специализированных политик ИБ, применяющихся в конкретной отрасли. Например, если говорить о банках, vGate R2 имеет следующие наборы политик, которые могут быть очень полезными:
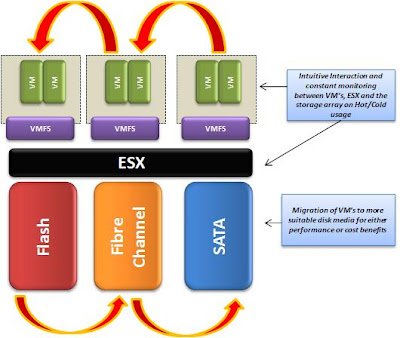
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.
Компания Veeam Software, известная своим продуктом для резервного копирования Veeam Backup and Replication, выпустила финальную версию решения Veeam ONE v6, предназначенного для мониторинга (бывший продукт Veeam Monitor), а также контроля изменений и автоматизированной отчетности (бывший продукт Veeam Reporter) виртуальных инфраструктур VMware vSphere и Microsoft Hyper-V. О новом комплекте поставки решения Veeam ONE мы уже писали тут и тут.
Функции мониторинга:
Функции отчетности:
Теперь два продукта Veeam Reporter и Monitor работают на одном движке с общей базой данных, что делает Veeam ONE законченным решением для управления виртуальной инфраструктурой с точки зрения мониторинга, отчетности, контроля изменений и планирования мощностей. Все в одном.
Новые возможности Veeam ONE v6:
Мониторинг
New monitoring views - новые представления дэшбордов summary, alarm и resource, позволяющие осуществлять быструю навигацию вглубь объектов.
Read-only access to monitoring clients - для клиентов, которым нужны только функции наблюдения за виртуальной средой, можно ограничить права на изменения объектов.
Logical groupings of performance counters - пользователь несколькими кликами может поместить на графики метрики различных категорий для отслеживания возможных зависимостей между ними.
Детализация
Detailed views - для многих объектов можно "проваливаться" вниз с максимальным уровнем детализации.
Child object status display - индикаторы статуса родительских объектов дают представление о том, что происходит с дочерними, и какие у них могут быть проблемы.
Generating reports from widgets - с помощью виджетов в Veeam ONE можно быстро сгенерировать отчет, отражающий заданный период времени.
Тревоги (Alarms)
New alarms - теперь еще большее количество алармов.
Default action - при срабатывании аларма автоматически посылается нотификация по почте всем, кто находится в группе default notification group.
Filtering - фильтры по тревогам могут быть основаны на базе error level, status, object type и времени.
Exclusions - исключения для алармов, которые можно применить к различным объектам: виртуальным дискам, сенсорам оборудования на хостах и т.п.
Email customization - редактирование поля subject и формата нотификаций.
Configurable email notification groups - можно задавать, кто получает нотификации по группам событий.
Отчетность
Overview reports - отчеты по Storage capacity, storage usage, а также обзорные отчеты infrastructure, hypervisor,
clusters и VMs.
Monitoring reports - отчеты по мониторингу: Alarms, uptime ВМ, производительность кластера, хостов и виртуальных машин, включая отчет по потребителям наибольшего количества ресурсов.
(VMware only) Optimization reports - ВМ с перевыделенными или недовыделенными ресурсами, снапшотами, лишними файлами, а также простаивающие ВМ и шаблоны, выключенные ВМ.
(VMware only) Change tracking reports - отслеживание изменений в настройках пользователем или объектом, а также изменения пермиссий.
Integration - дэшборды можно встраивать в письма оповещений, веб-порталы и сторонние приложения.
Access control - для доступа к дэшбордам могут быть заданы разрешения для пользователей.
Автоматическое обновление и бизнес-категоризация
Automatic updates - по запросу Veeam ONE v6 проверяет и загружает обновления репорт-паков, дэшбордов и виджетов.
Business views - представления мониторинга и отчетности могут быть настроены в соответствии с категоризацией, заданной пользователем. Т.е. эти представления можно сделать на основе бизнес или географических критериев.
Standalone hosts - отдельно стоящие хост-серверы также включаются в категоризацию.
Sample categorization - схема бизнес-категоризации, которая показывает пример, как это делать.
Сбор данных в виртуальной среде
Automatically triggered data collection - после установки Veeam ONE сразу же начинается периодический сбор данных с хост-серверов.
Controlled query load - данные о производительности и конфигурации собираются в различных задачах, что позволяет более гибко подходить к распределению нагрузки этими задачами на хост-серверы.
Granular performance history - в Veeam ONE v6 сохраняется гранулярная история производительности за длительный промежуток времени, включающая в себя данные мониторинга и отчетности.
Поддержка VMware vSphere 5
Datastore maximum queue depth - Veeam ONE v6 включает эту новую метрику vSphere 5.
Storage clusters - мониторинг и оповещения по кластерам хранилищ vSphere 5.
Поддержка Microsoft Hyper-V
Alarms - Veeam ONE имеет 90 алармов для хостов и других объектов Hyper-V.
Full monitoring support for Failover Clusters - для кластеров Hyper-V поддерживаются все функции мониторинга, включая алармы, отчеты, чарты и статьи базы знаний для томов CSV.
Direct collection of performance data - данные о производительности собираются напрямую с хост-серверов, включая хосты без SC VMM, что позволяет контролировать больше, чем сам SC VMM.
Решение Veeam ONE v6 для Microsoft Hyper-V и VMware vSphere можно скачать по одной ссылке тут.
На днях появилась бета-версия продукта StarWind iSCSI SAN 5.9, средства номер 1 для создания отказоустойчивых хранилищ iSCSI под виртуальные машины VMware vSphere и Microsoft Hyper-V. Традиционно, несмотря на то что версия StarWind 5.8 вышла совсем недавно, нас ожидает множество нововведений и улучшений. Данная версия пока для VMware, под Hyper-V (Native SAN) выйдет немного позже.
Итак, новые возможности StarWind iSCSI 5.9, доступные в бете:
1. Трехузловой кластер высокой доступности хранилищ, еще больше повышающий надежность решения. При этом все три узла являются активными и на них идет запись. Диаграмма:
По обозначенным трем каналам синхронизации данные хранилищ синхронизируются между собой. Также все узлы обмениваются друг с другом сигналами доступности (Heartbeat).
2. Репликация на удаленный iSCSI Target через WAN-соединение с поддержкой дедупликации. Эта функция пока экспериментальная, но данная возомжность часто требуется заказчиками для катастрофоустойчивых решений хранилищ.
3. Поддержка механизмом дедупликации данных, которые удаляются с хранилищ - неиспользуемые блоки перезаписываются актуальными данными.
4. Использование памяти механизмом дедупликации сократилось на 30%. Теперь необходимо 2 МБ памяти на 1 ГБ дедуплицируемого хранилища при использовании блока дедупликациии 4 КБ.
5. StarWind SMI-S agent, доступный для загрузки как отдельный компонент. Он позволяет интегрировать StarWind в инфраструктуру Systme Center Virtual Machine Manager (SC VMM), добавив StarWind Storage Provider, реализующий задачи управления таргетами и хранилищами.
6. Как пишут на форуме, появилась полноценная поддержка механизма ALUA, работа с которым идет через SATP-плагин VMW_SATP_ALUA (подробнее об этом тут).
Скачать бета версию StarWind iSCSI SAN 5.9 можно по этой ссылке.
Rob de Veij, выпускающий бесплатную утилиту для настройки и аудита виртуальной инфраструктуры VMware vSphere (о ней мы не раз писали), выпусил обновление RVTools 3.3. Кстати, со времен выпуска версии 3.0, RVTools научилась поддерживать ESXi 5.0 и vCenter 5.0.
Новые возможности RVTools 3.3:
Таймаут GetWebResponse увеличен с 5 минут до 10
Новая вкладка с информацией о HBA-адаптерах (на картинке выше)
Приведена в порядок вкладка vDatastore
Функция отсылки уведомлений по почте RVToolsSendMail поддерживает несколько получателей через запятую
Информация о папке VMs and Templates показывается на вкладке vInfo
Несколько исправлений багов
Скачать полезную и бесплатную RVTools 3.3 можно по этой ссылке. Что можно увидеть на вкладках описано здесь.
Мы уже не раз писали о продукте номер 1 - vGate R2, который является лидером на рынке защиты виртуальных инфраструктур за счет средств автоматической настройки виртуальной среды VMware vSphere и механизмов защиты от несанкционированного доступа. Сегодня мы поговорим о резервировании сервера авторизации vGate R2. Сервер авторизации - это основной компонент vGate R2, который осуществляет авторизацию и аутентификацию пользователей, без которого нельзя будет администрировать среду VMware vSphere, если он вдруг выйдет из строя. Он выполняет следующие функции...
Таги: Security Code, Security, VMware, vSphere, HA, ESXi, vGate
Компания VMware еще 14 апреля запустила портал самообслуживания пользователей, где они могут управлять своими лицензионными ключами (регистрировать, даунгрейдить) и работать с технической поддержкой по продуктам VMware, который называется My VMware.
Как видно из картинки, вход на портал доступен с основной страницы сайта VMware. Также на него можно зайти по адресу:
Зарегистрировавшись на этом портале, пользователь получает доступ к интерфейсу управления лицензионными ключами продуктов, контрактами технической поддержки и пользователями организации. Пользователи организации разделяются на различные категории, для которых определяются роли, которым позволено смотреть лицензионные ключи, проводить с ними операции (даунгрейд, комбинирование, разделение и т.п.). Оттуда же можно сформировать запрос на продление поддержки (SnS) и написать в поддержку.
В общем, для тех, кто является пользователем продуктов Citrix, скажем, что это, по-сути, то же самое, что и MyCitrix, может даже несколько больше.
Партнеры VMware, которые регистрируются как отдельная категория пользователей, получают еще и доступ к различным партнерским инструментам для продаж, маркетинга и прочее. Штука эта очень насыщенная всяким функционалом, поэтому если вы покупали VMware vSphere и прочие продукты или продаете их - советую зарегистрироваться там.
В последнее время вышло просто море статей KB по использованию My VMware, приведем наиболее полезные из них:
Вот видео с обзором навигации по My VMware. Как всегда сделано так, чтобы ничего не было видно, но основные секции понятны:
А вот так, например, можно самостоятельно даунгрейдить лицензии:
Эта штука всем хороша, кроме одного - она не работает. Например, мои креды не подхватились, при сбросе пароля (2 раза) - залогиниться я никуда не смог. Много лет назад мы также сдавали проект госкомиссии - открыли страницу сайта, а залогиниться не смогли. Рассказывали образами. Вот так и VMware показывает мне только видео.
И, напоследок, гвоздь программы. My VMware - смешная кнопка:
Для решения этой проблемы нам предлагают почистить кэш браузера (фантастика - есть статья KB как справиться с кнопкой). Но даже если вы с ней справитесь, то хрен залогинитесь.
Таги: VMware, My VMware, vSphere, Enterprise, Licensing
Мы уже писали о том, как сбросить пароль root на VMware ESX версии 4.0 и 4.1 в случае, если вы забыли его (тут для single user mode). Теперь появилась еще одна инструкция от Бернарда, которая аналогична предыдущей от Дэйва и работает для VMware ESXi 5.0. Перед тем, как сбросить пароль на VMware ESXi, надо понимать, что приведенная ниже инструкция может привести к неподдерживаемой со стороны VMware конфигурации, о чем прямо написано в KB 1317898.
Итак восстановление пароля на хосте ESXi 5.0:
1. Хэш пароля хранится в файле etc/shadow, который хранится в архиве local.tgz, который хранится в архиве state.tgz:
2. Загружаем сервер ESXi с какого-нибудь Live CD (например, GRML), используя CD/DVD или USB-флешку.
3. После загрузки находим и монтируем раздел VFAT инсталляции ESXi, содержащий файл state.tgz. Например, он может быть на разделе Hypervisor3:
6. В результате распаковки получим директорию /etc, в которой есть файл shadow. Открываем его в vi для редактирования:
vi etc/shadow
Удаляем хэш пароля root (до двоеточия перед цифрами). Было:
Стало:
7. Сохраняем резервную копию state.tgz и перепаковываем архив:
mv /mnt/Hypervisor3/state.tgz /mnt/Hypervisor3/state.tgz.bak
rm local.tgz
tar czf local.tgz etc
tar czf state.tgz local.tgz
mv state.tgz /mnt/Hypervisor3/
8. Перезагружаем сервер и уже загружаемся в VMware ESXi 5.0. Видим такую картинку при соединении из vSphere Client:
Это значит, что все получилось. Теперь можем заходить в консоль под пользователем root с пустым паролем. Работает эта штука и для VMware ESXi 5.0 Upfate 1.
Как известно, компания VMware уже довольно давно выпускает руководство по обеспечению информационной безопасности VMware vSphere Security Hardening Guide (тут и тут), содержащее список потенциальных угроз ИБ и их возможное влияние на инфраструктуру виртуализации. Также доступен Security Hardening Guide для VMware View и vCloud Director.
Виртуальные машины (настройки, устройства, интерфейсы, VMware Tools)
Хосты VMware ESXi (доступ к управлению, логи, хранилища)
Сетевое взаимодействие (включая распределенный коммутатор dvSwitch)
Сервер управления vCenter (доступ к управляющим компонентам и т.п.)
На данный момент руководство доступно в виде xlsx-табличек:
Основная страница обсуждения документа находится здесь.
Кроме того, вчера же появился и документ "vSphere Hardening Guide: 4.1 and 5.0 comparison", отражающий основные отличия руководства для версий 4.1 и 5.0. Там хорошо видно, какие новые фичи vSphere 5 покрывает новая версия документа:
Соответственно, можно ожидать скорого появления обновленных версий продуктов vGate R2 и vGate Compliance Checker, позволяющих проверить соответствия вашей инфраструктуры нормам данного руководящего документа и настроить виртуальную инфраструктуру VMware vSphere в соответствии с ними средствами политик.
При эксплуатации виртуальной инфраструктуры VMware vSphere иногда случается ситуация, когда виртуальную машину нельзя включить из-за того, что ее какой-нибудь из ее файлов оказывается залоченным. Происходит это при разных обстоятельствах: неудачной миграции vMotion / Storage vMotion, сбоях в сети хранения и прочих.
Наиболее распространенная ошибка при этом выглядит так:
Could not power on VM: Lock was not free
Встречаются также такие вариации сообщений и ошибок при попытке включения виртуальной машины, которое зависает на 95%:
Unable to open Swap File
Unable to access a file since it is locked
Unable to access a file <filename> since it is locked
Unable to access Virtual machine configuration
Ну а при попытке соединения с консолью ВМ получается вот такое:
Error connecting to <path><virtual machine>.vmx because the VMX is not started
Все это симптомы одной проблемы - один из следующих файлов ВМ залочен хост-сервером VMware ESXi:
<VMNAME>.vswp
<DISKNAME>-flat.vmdk
<DISKNAME>-<ITERATION>-delta.vmdk
<VMNAME>.vmx
<VMNAME>.vmxf
vmware.log
При этом залочил файл не тот хост ESXi, на котором машина зарегистрирована. Поэтому решение проблемы в данном случае - переместить ВМ холодной миграций на тот хост, который залочил файл и включить ее там, после чего уже можно переносить ее куда требуется. Но как найти тот хост ESXi, который залочил файл? Об этом и рассказывается ниже.
Поиск залоченного файла ВМ
Хорошо если в сообщении при запуске виртуальной машины вам сообщили, какой именно из ее файлов оказался залоченным (как на картинке выше). Но так бывает не всегда. Нужно открыть лог vmware.log, который расположен в папке с виртуальной машиной, и найти там строчки вроде следующих:
Failed to initialize swap file : Lock was not free
Тут видно, что залочен .vswp-файл ВМ.
За логом на экране можно следить командой (запустите ее и включайте ВМ):
tail /vmfs/volumes/<UUID>/<VMDIR>/vmware.log
Проверка залоченности файла ВМ и идентификация владельца лока
После того, как залоченный файл найден, нужно определить его владельца. Сначала попробуем команду touch, которая проверяет, может ли бы обновлен time stamp файла, т.е. можно ли его залочить, или он уже залочен. Выполняем следующую команду:
# touch /vmfs/volumes/<UUID>/<VMDIR>/<filename>
Если файл уже залочен, мы получим вот такое сообщение для него:
В значении "owner" мы видим MAC-адрес залочившего файл хоста VMware ESXi (выделено красным). Ну а как узнать MAC-адрес хоста ESXi - это вы должны знать. Дальше просто делаем Cold Migration виртуальной машины на залочивший файл хост ESXi и включаем ее там.
Те, кто хочет дальше изучать вопрос, могут проследовать в KB 10051.
Продолжаем рассказывать о продукте vGate R2 для защиты виртуальных инфраструктур от компании Код Безопасности. Он позволяет автоматизировать настройку безопасной конфигурации хост-серверов, хранилищ, сетей и виртуальных машин в инфраструктуре VMware vSphere 5, а также защитить ее от несанкционированного доступа.
Сегодня мы продолжаем разговор о безопасности и облачных инфраструктурах. Хотим обратить вниманию на статью небезызвестной Марии Сидоровой "Противоречивые облака":
Виртуализация на платформе VMware vSphere позволяет владельцам облачных ЦОД предложить своим клиентам эффективные решения для бизнеса. Практически неограниченная масштабируемость ресурсов в сочетании с эффективной моделью оплаты (pay-as-you-go), предлагаемой в модели облачных сервисов, делает услуги виртуализированных облачных ЦОД, построенных с использованием технологий VMware, привлекательными для многих корпоративных пользователей. И мы с вами видели уже немало примеров облаков на базе продуктов VMware с соответсвующими показателями уровня обслуживания (SLA), которые существенно превосходят те, что можно обеспечить в средней компании.
Тем не менее, недоверие компаний к уровню обеспечения безопасности информации в облачных инфраструктурах - это одна из основных причин того, что только ограниченное количество компаний принимает решение о переходе на использование этой модели.
Облачная модель в понимании корпоративных заказчиков соотносится со многими рисками информационной безопасности. Среди наиболее актуальных для компаний ИБ-рисков, препятствующих переходу на облачную модель, можно перечислить следующие:
риски в области целостности данных, сохранности данных, восстановления данных;
риски несанкционированного доступа к данным;
риски невыполнения требований стандартов безопасности и регулирующего законодательства;
риски ненадлежащего аудита и оценки соответствия стандартам и лучшим практикам (PCI DSS, CIS Networking и др.);
риск возникновения несоответствия корпоративным политикам безопасности.
Все эти проблемы, в той или иной степени, позволяет решать продукт vGate R2, бесплатную пробную версию которого можно скачать по этой ссылке. А в статье вы найдете ответы на вопросы о том, как это делается. И почитайте вот эту нашу статью.
Еще один момент - в vGate R2 уже есть поддержка альтернативного метода лицензирования на базе платы за виртуальную машину за месяц (по модели SaaS). То есть уже сейчас, если вы являетесь сервис-провайдером, предлагающим виртуальные машины в аренду (например, по программе VSPP), вы можете обратиться в компанию Код Безопасности с вопросом о том, как по модели SaaS платить за сервисы обеспечения безопасности вашего ЦОД.
Компания VMware в базе знаний опубликовала интересный плакат "VMware vSphere 5 Memory Management and Monitoring diagram", раскрывающий детали работы платформы VMware vSphere 5 с оперативной памятью серверов. Плакат доступен как PDF из KB 2017642:
Основные техники оптимизации памяти хостов ESXi, объясняемые на плакате:
Есть также интересная картинка с объяснением параметров вывода esxtop, касающихся памяти (кликабельно):
Пишут, что администраторы VMware vSphere скачивают его, распечатывают в формате A2 и смотрят на него время от времени, как на новые ворота. Таги: VMware, vSphere, Memory, ESX, esxtop, VMachines, Whitepaper, Diagram
Ключевые особенности продукта от Symantec - возможность динамической балансировки запросов ввода-вывода с хоста по нескольким путям одновременно, поддержка работы с основными дисковыми массивами, представленными на рынке, и возможность учитывать характеристики хранилищ (RAID, SSD, Thin Provisioning).
Как можно узнать из нашей статьи про PSA, Veritas Dynamic Multi-Pathing (DMP) - это MPP-плагин для хостов ESXi:
Veritas DMP позволяет интеллектуально балансировать нагрузку с хостов ESXi в SAN, обеспечивать непрерывный мониторинг и статистику по путям в реальном времени, автоматически восстанавливать путь в случае сбоя и формировать отчетность через плагин к vCenter обо всех хранилищах в датацентре. Что самое интересное - это можно будет интегрировать с физическим ПО для доступа по нескольким путям (VxVM) в единой консоли.
Всего в Veritas DMP существует 7 политик для балансировки I/O-запросов, которые могут быть изменены "на лету" и позволят существенно оптимизировать канал доступа к хранилищу по сравнению со стандартным плагином PSP от VMware. Кстати, в терминологии Symantec, этот продукт называется - VxDMP.
Стоимость этой штуки - от 900 долларов за четырехъядерный процессор хоста (цена NAM). Полезные ссылки:
Как знают администраторы VMware vSphere в крупных компаниях, в этой платформе виртуализации есть фреймворк, называющийся VMware Pluggable Storage Architecture (PSA), который представляет собой модульную архитектуру работы с хранилищами SAN, позволяющую использовать ПО сторонних производителей для работы с дисковыми массивами и путями.
Выглядит это следующим образом:
А так понятнее:
Как видно из второй картинки, VMware PSA - это фреймворк, работа с которым происходит в слое VMkernel, отвечающем за работу с хранилищами. Расшифруем аббревиатуры:
VMware NMP - Native Multipathing Plug-In. Это стандартный модуль обработки ввода-вывода хоста по нескольким путям в SAN.
Third-party MPP - Multipathing plug-in. Это модуль стороннего производителя для работы по нескольким путям, например, EMC Powerpath
VMware SATP - Storage Array Type Plug-In. Это часть NMP от VMware (подмодуль), отвечающая за SCSI-операции с дисковым массивом конкретного производителя или локальным хранилищем.
VMware PSP - Path Selection Plug-In. Этот подмодуль NMP отвечает за выбор физического пути в SAN по запросу ввода-вывода от виртуальной машины.
Third-party SATP и PSP - это подмодули сторонних производителей, которые исполняют означенные выше функции и могут быть встроены в стандартный NMP от VMware.
MASK_PATH - это модуль, который позволяет маскировать LUN для хоста VMware ESX/ESXi. Более подробно о работе с ним и маскировании LUN через правила написано в KB 1009449.
Из этой же картинки мы можем заключить следующее: при выполнении команды ввода-вывода от виртуальной машины, VMkernel перенаправляет этот запрос либо к MPP, либо к NMP, в зависимости от установленного ПО и обращения к конкретной модели массива, а далее он уже проходит через подуровни SATP и PSP.
Уровень SATP
Это подмодули, которые обеспечивают работу с типами дисковых массивов с хоста ESXi. В составе ПО ESXi есть стандартный набор драйверов, которые есть под все типы дисковых массивов, поддерживаемых VMware (т.е. те, что есть в списке совместимости HCL). Кроме того, есть универсальные SATP для работы с дисковыми массивами Active-active и ALUA (где LUN'ом "владеет" один Storage Processor, SP).
Каждый SATP умеет "общаться" с дисковым массивом конкретного типа, чтобы определить состояние пути к SP, активировать или деактивировать путь. После того, как NMP выбрал нужный SATP для хранилища, он передает ему следующие функции:
Мониторинг состояния каждого из физических путей.
Оповещение об изменении состояний путей
Выполнение действий, необходимый для восстановления пути (например failover на резервный путь для active-passive массивов)
Посмотреть список загруженных SATP-подмодулей можно командой:
esxcli nmp satp list
Уровень PSP
Path Selection Plug-In отвечает за выбор физического пути для I/O запросов. Подмодуль SATP указывает PSP, какую политику путей выставить для данного типа массива, в зависимости от режима его работы (a-a или a-p). Вы можете переназначить эту политику через vSphere Client, выбрав пункт "Manage Paths" для устройства:
Для LUN, презентуемых с массивов Active-active, как правило, выбирается политика Fixed (preferred path), для массивов Active-passive используется дефолтная политика Most Recently Used (MRU). Есть также и еще 2 политики, о которых вы можете прочитать в KB 1011340. Например, политика Fixed path with Array Preference (VMW_PSP_FIXED_AP) по умолчанию выбирается для обоих типов массивов, которые поддерживают ALUA (EMC Clariion, HP EVA).
Надо отметить, что сторонний MPP может выбирать путь не только базовыми методами, как это делает VMware PSP, но и на базе статистического интеллектуального анализа загрузки по нескольким путям, что делает, например, ПО EMC Powerpath. На практике это может означать рост производительности доступа по нескольким путям даже в несколько раз.
Работа с фреймворком PSA
Существуют 3 основных команды для работы с фреймворком PSA:
esxcli, vicfg-mpath, vicfg-mpath35
Команды vicfg-mpath и vicfg-mpath35 аналогичны, просто последняя - используется для ESX 3.5. Общий список доступных путей и их статусы с информацией об устройствах можно вывести командой:
vicfg-mpath -l
Через пакет esxcli можно управлять путями и плагинами PSA через 2 основные команды: corestorage и nmp.
Надо отметить, что некоторые команды esxcli работают в интерактивном режиме. С помощью nmp можно вывести список активных правил для различных плагинов PSA (кликабельно):
esxcli corestorage claimrule list
Есть три типа правил: обычный multipathing - MP (слева), FILTER (аппаратное ускорение включено) и VAAI, когда вы работаете с массивом с поддержкой VAAI. Правила идут в порядке возрастания, с номера 0 до 101 они зарезервированы VMware, пользователь может выбирать номера от 102 до 60 000. Подробнее о работе с правилами можно прочитать вот тут.
Правила идут парами, где file обозначает, что правило определено, а runtime - что оно загружено. Да, кстати, для тех, кто не маскировал LUN с версии 3.5. Начиная с версии 4.0, маскировать LUN нужно не через настройки в vCenter на хостах, а через объявление правил для подмодуля MASK_PATH.
Для вывода информации об имеющихся LUN и их опциях в формате PSA можно воспользоваться командой:
esxcli nmp device list
Можно использовать всю ту же vicfg-mpath -l.
Ну а для вывода информации о подмодулях SATP (типы массивов) и PSP (доступные политики путей) можно использовать команды:
esxcli nmp satp list
esxcli nmp psp list
Ну а дальше уже изучайте, как там можно глубже копать. Рекомендуемые документы:

 RSS
RSS